def calculate_loss_fn(loss_fn, logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
shift_logits = logits[:, :-1, :].contiguous()
shift_labels = labels[:, 1:].contiguous()
return loss_fn(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))Fine Tuning T5 for Grammar Correction
Deep Learning
LLM
Fine-tuning T5 for Sequence to Sequence tasks

Introduction
You may have read my previous post on fine tuning GPT-2 for grammar correction. Well, I am here to tell you I have made a terrible mistake. While it was a fun exercise to understand the intricacies of GPT-2, I butchered it into correcting grammar. Let me explain why.
Firstly, GPT-2 is a decoder only model. Meaning the current token can only attend previous tokens. While this is fine for our task by adding a seperator token, this also means that the decoder model needs to understand AND reconstruct the sentence. Therefore performing two tasks. T5 on the other has an encoder-decoder architecture. The encoder only contains an input task and the decoder only has a output/ generative task. Therefore dividing the responsibilities.
T5 is also trained to as a multi task model which does things like summarization, translation etc. 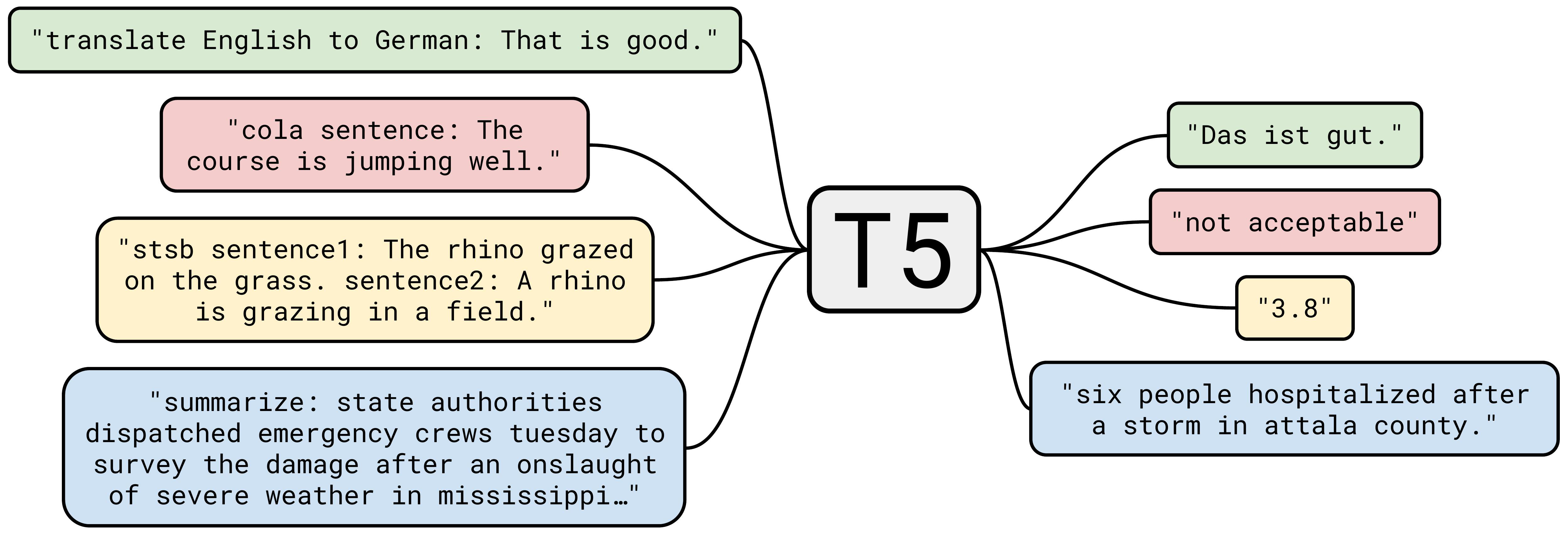
Data
Setting up the data is no different to what we did during GPT-2. We will still use the c4_200m dataset from huggingface datasets, and we will still try to match input to a corrected output, while also trying to teach the model when to leave it alone when it sees a good sentence.
Loss function
However, we now come to the first gotcha. The loss function. While in GPT-2 we can use outputs.loss we cannot do so here. That is because HF does not interally shift the tokens for a autoregressive task like generation. Instead, it is expecting a missing token prediction task by default. The following function simply shifts the labels 1 across, so that we can predict one token ahead. The loss function is your standard cross entropy loss.
To dive into this deeper, the model predicts what the next token ought to be. Therefore, the shape of the output is [batch_size, sequence_length, all_possible_tokens]. If you are wondering why it’s not [batch_size, sequence_length, hidden_dim_size], that’s because in this class of HF models (generative, specifically in this case, transformers.T5ForConditionalGeneration) have one more layer of shape [hidden_dim_size, all_possible_tokens] over which a softmax layer is used to get a probability over the tokens. This last layer is often simply the input embeddings transposed.
The naive method to use the training data here would be to simply use the bad sentence as an input and the good sentence as the output. However, the model should also recognise when to leave a good sentence as is. Therefore, we calculate loss once for each scenario described and sum them up.
This brings us to the second gotcha. When I trained the first time around I simply used the tokenized sentence of the input/ output sentence. It fortunately trained well and masked a serious mathematical error. That was during inference, when we call the model.generate(...) function, it always starts off with a special token in the decoder. This could be accessed via model.config.decoder_start_token_id. Therefore, during training we need to prepend this token to the output sentence. We can see this in the LightningModule below.
Code
class LightningModule(pl.LightningModule):
def __init__(
self,
model: nn.Module,
tokenizer: Tokenizer,
generation_kwargs: Dict[str, Any],
lr: float,
loss_fn: Callable = nn.CrossEntropyLoss(),
) -> None:
super().__init__()
self.model = model
self.tokenizer = tokenizer
self.lr = lr
self.generation_kwargs = generation_kwargs
self.loss_fn = loss_fn
self.prepend_sentence = PREPEND_SENTENCE
decoder_start_token_id = model.config.decoder_start_token_id
self.prepend_input_ids = torch.LongTensor([decoder_start_token_id] * BATCH_SIZE)[:, None]
self.prepend_attention_masks = torch.LongTensor([1] * BATCH_SIZE)[:, None]
self.model.train()
if IS_FREEZE_LAYERS:
for layer in self.model.encoder.block[:FREEZE_LAYERS]:
layer.eval()
for p in layer.parameters():
p.requires_grad = False
for layer in self.model.decoder.block[:FREEZE_LAYERS]:
layer.eval()
for p in layer.parameters():
p.requires_grad = False
self.table_logging = 0
def prepend_tokens(self, tokenized_batch: Dict[str, torch.LongTensor], len_batch: int) -> Dict[str, torch.LongTensor]:
input_ids = torch.cat(
[
self.prepend_input_ids[:len_batch, :].to(self.device),
tokenized_batch["input_ids"],
],
dim=-1,
)
attention_mask = torch.cat(
[
self.prepend_attention_masks[:len_batch, :].to(self.device),
tokenized_batch["attention_mask"],
],
dim=-1,
)
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
def get_loss(self, input_sentences: List[str], output_sentences: List[str]) -> torch.FloatTensor:
tokenized_input = self.tokenizer(
[self.prepend_sentence + sentence for sentence in input_sentences],
self.device
)
tokenized_output = self.prepend_tokens(self.tokenizer(output_sentences, self.device), len(output_sentences))
labels = tokenized_output["input_ids"].clone()
labels[tokenized_output["attention_mask"] == 0] == LABEL_MASK
out = self.model(
input_ids=tokenized_input["input_ids"],
attention_mask=tokenized_input["attention_mask"],
decoder_input_ids=tokenized_output["input_ids"],
decoder_attention_mask=tokenized_output["attention_mask"],
)
return calculate_loss_fn(self.loss_fn, out.logits, labels)
def common_step(self, batch: Dict[str, str]) -> torch.Tensor:
bad_grammar_loss = self.get_loss(batch["input"], batch["output"])
good_grammar_loss = self.get_loss(batch["output"], batch["output"])
return good_grammar_loss + bad_grammar_loss
def training_step(
self, batch: Dict[str, torch.LongTensor], batch_idx: int,
) -> torch.Tensor:
loss = self.common_step(batch)
self.log("training_loss", loss, on_step=True, on_epoch=True, batch_size=len(batch["input"]))
return loss
def validation_step(
self, batch: Tuple[torch.Tensor, List[str]], batch_idx: int,
) -> torch.Tensor:
loss = self.common_step(batch)
self.log("validation_loss", loss, on_step=False, on_epoch=True, batch_size=len(batch["input"]))
if batch_idx == 0:
self.log_examples(batch)
def log_examples(self, batch):
good_grammar_batch = self.tokenizer(batch["output"], device=self.device)
bad_grammar_batch = self.tokenizer(batch["input"], device=self.device)
encoded_good_outputs = self.model.generate(**good_grammar_batch, **self.generation_kwargs)
encoded_bad_outputs = self.model.generate(**bad_grammar_batch, **self.generation_kwargs)
generated_good_sentences = self.tokenizer.batch_decode(encoded_good_outputs)
generated_bad_sentences = self.tokenizer.batch_decode(encoded_bad_outputs)
columns = ["good input", "good output", "bad input", "bad output"]
data = [
[good_input, good_output, bad_input, bad_output]
for good_input, good_output, bad_input, bad_output in zip(
batch["output"], generated_good_sentences, batch["input"], generated_bad_sentences
)
]
table = wandb.Table(data=data, columns=columns)
if self.logger is not None:
self.table_logging += 1
self.logger.experiment.log({f"epoch {self.table_logging} results": table})
def configure_optimizers(self) -> torch.optim.Optimizer:
if IS_FREEZE_LAYERS:
return adam.FusedAdam(
[
{"params": layer.parameters(), "lr": self.lr} for layer in language_model.encoder.block[FREEZE_LAYERS:]
] + \
[
{"params": layer.parameters() , "lr": self.lr} for layer in language_model.decoder.block[FREEZE_LAYERS:]
]
)
else:
return adam.FusedAdam(self.model.parameters(), self.lr)Training the model
The last gotcha comes from during the training, it seems using 16 bit training is unstable. Therefore, I was forced to use 32 bit with a smaller batch size, but this can be remedied by increasing the accumulate_grad_batches.
Also as a side note, I do like to freeze certain layers, a trick I picked up in fast.ai. This is done in order to not overfit my training data. Conceptually, it makes sense not to train embeddings since some words will be seen (and therefore updated) more often than other.
Code
adam.FusedAdam(
[
{"params": layer.parameters(), "lr": self.lr} for layer in language_model.encoder.block[FREEZE_LAYERS:]
] + \
[
{"params": layer.parameters() , "lr": self.lr} for layer in language_model.decoder.block[FREEZE_LAYERS:]
]
)Results
Accoring to the limited experiments that I ran, it seems T5 does better than Flan-T5. Keep in mind that this was a drop in replacement during training. In the following examples it seems to be doing a decent job of leaving some text as is while redoing others. 
However, let me add that Flan-T5 is magical! If you read the paper it is supposed to generalise to unseen tasks. The original T5 paper was only tasked with 5 tasks, whereas there were many tasks than Flan-T5 was trained with the same footprint in terms of number of weights. As you can see in the following, simply by adding Correct grammar in following sentence: I was able to get a corrected sentence in Flan-T5-large model. 
Summary
In closing the two main take away points are: 1. Redo the loss calculation. 2. Change to 32 bit training/ try bfloat16.
If you can afford to pay for training it is worth trying to train Flan-T5 for longer and see where it gets to. My wandb logs can be seen here and the kaggle kernel can be found here.
Shameless Self Promotion
If you enjoyed the tutorial buy my course (30 days moneyback).