Blog






Vison Language Models from Scratch
Deep Learning
LLM
huggingface
Multimodal














DINO Self Supervised Vision Transformers
pytorch
Loss Function


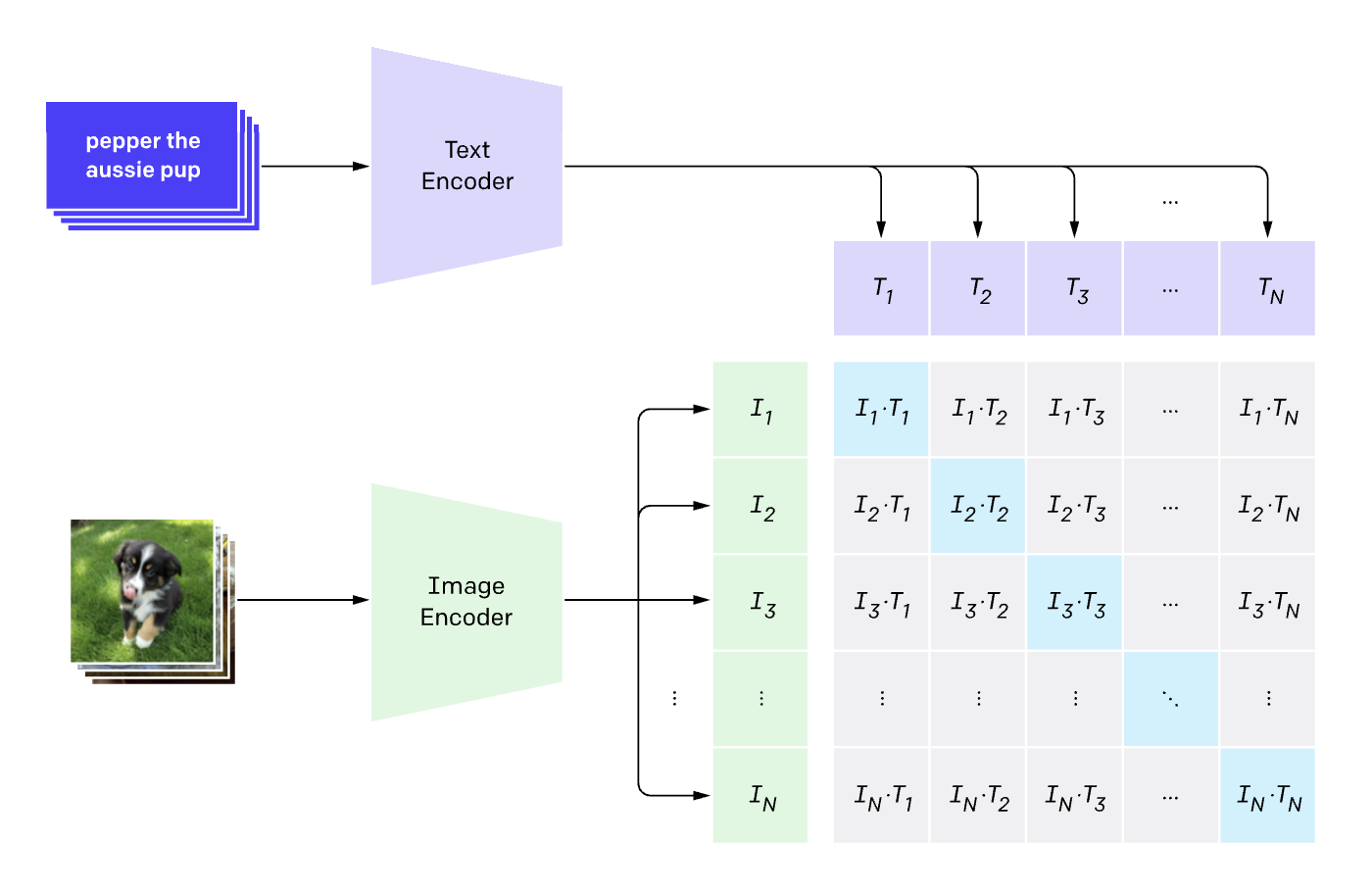
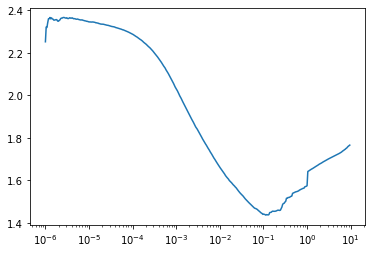
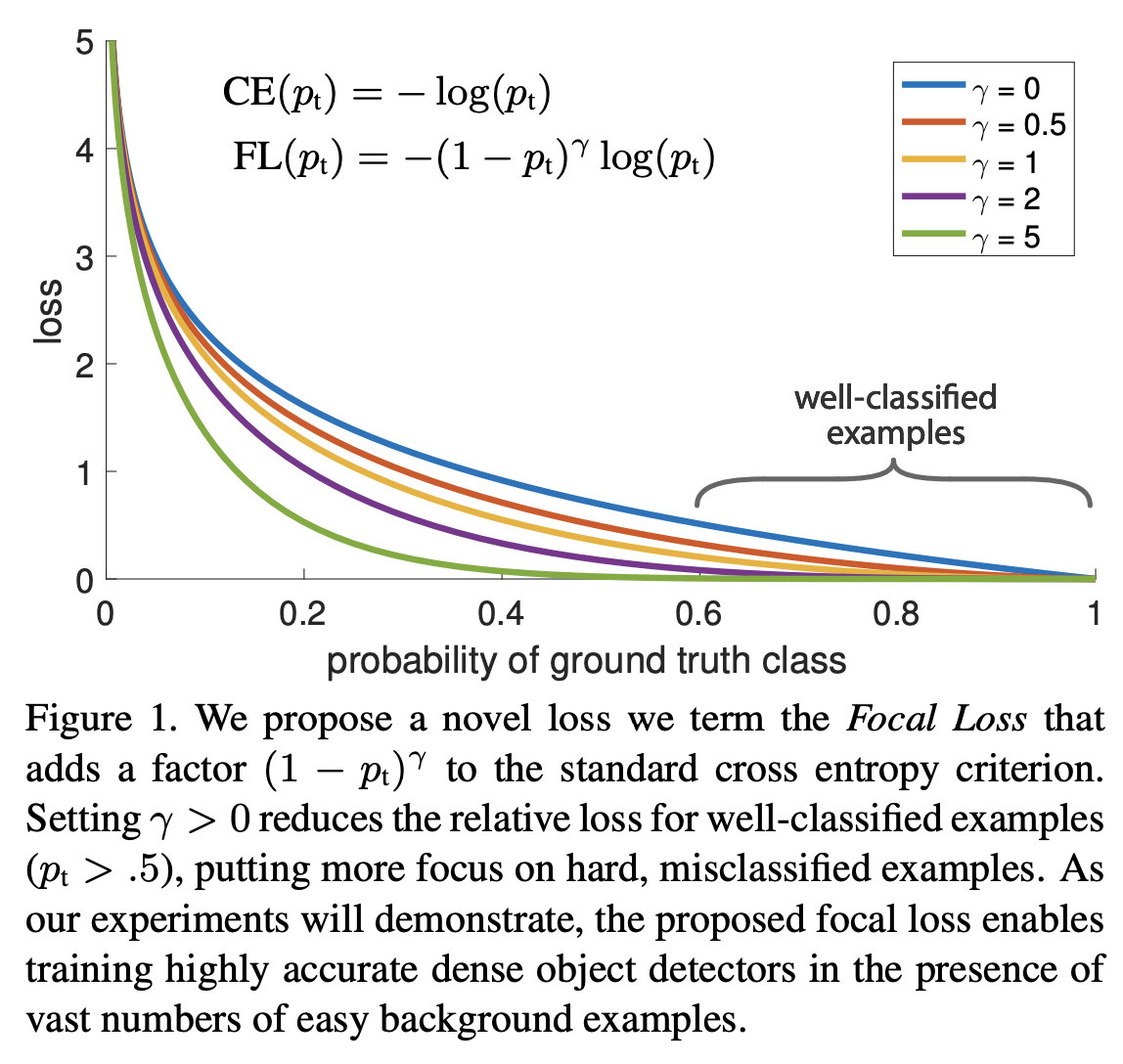

No matching items